


Why use Puppet desired state management?
There are many benefits to implementing a declarative configuration tool like Puppet into your environment — most notably consistency and automation.
- Consistency. Troubleshooting problems with servers is a time-consuming and manually intensive process. Without configuration management, you are unable to make assumptions about your infrastructure — such as which version of Apache you have or whether your colleague configured the machine to follow all the manual steps correctly. But when you use configuration management, you are able to validate that Puppet applied the desired state you wanted. You can then assume that state has been applied, helping you to identify why your model failed and what was incomplete, and saving you valuable time in the process. Most importantly, once you figure it out, you can add the missing part to your model and ensure that you never have to deal with that same problem again.
- Automation. When you manage a set of servers in your infrastructure, you want to keep them in a certain state. If you only have to manage homogeneous 10 servers, you can do so with a script or by manually going into each server. In this case, a tool like Puppet may not provide much extra value. But if you have 100 or 1,000 servers, a mixed environment, or you have plans to scale your infrastructure in the future, it is difficult to do this manually. This is where Puppet can help you — to save you time and money, to scale effectively, and to do so securely.
The Puppet platform
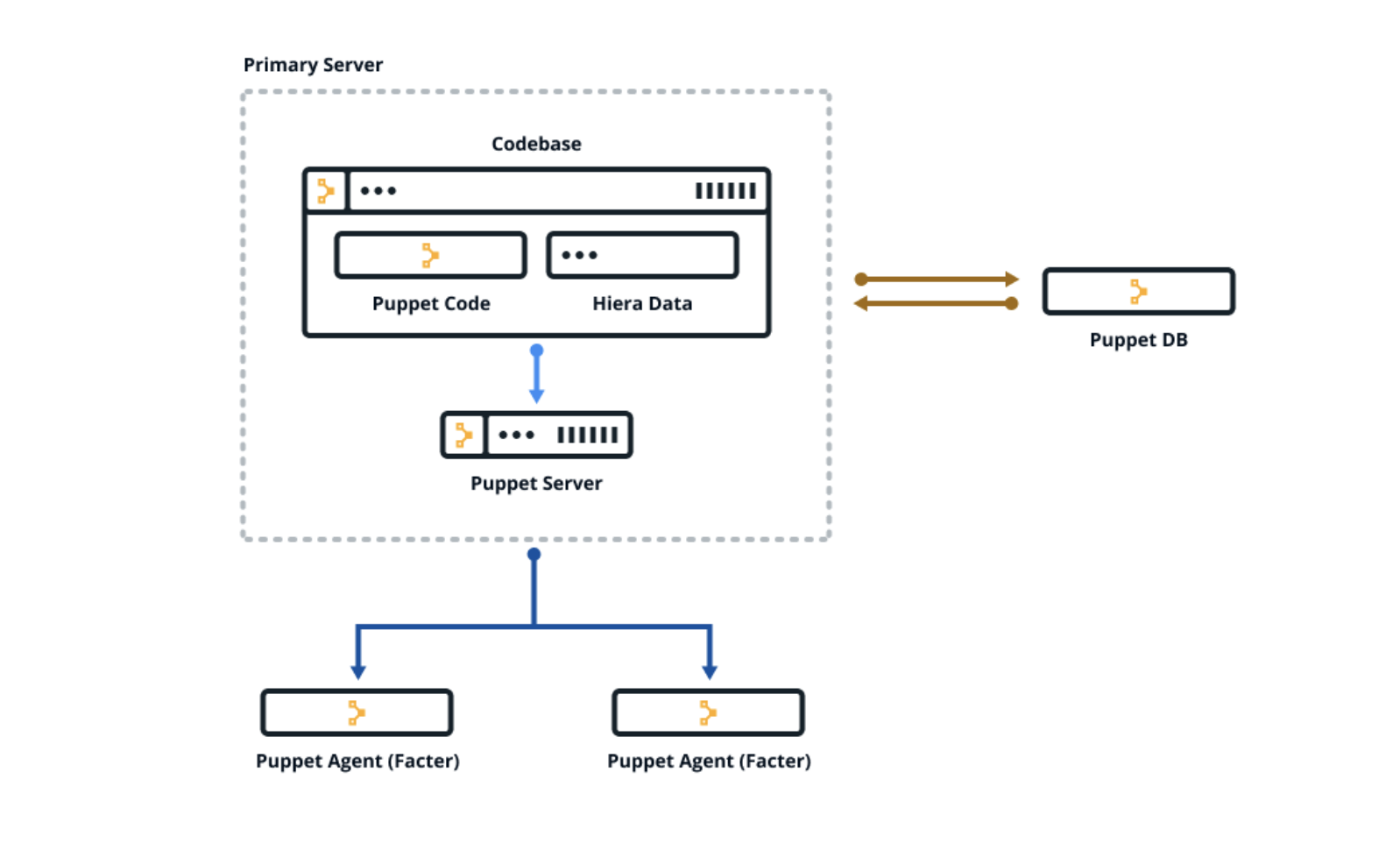
Puppet is made up of several packages. Together these are called the Puppet platform, which is what you use to manage, store and run your Puppet code. These packages include puppetserver, puppetdb, and puppet-agent — which includes Facter and Hiera.
Puppet is configured in an agent-server architecture, in which a primary node (system) controls configuration information for one or more managed agent nodes. Servers and agents communicate by HTTPS using SSL certificates. Puppet includes a built-in certificate authority for managing certificates. Puppet Server performs the role of the primary node and also runs an agent to configure itself.
Facter, Puppet’s inventory tool, gathers facts about an agent node such as its hostname, IP address, and operating system. The agent sends these facts to the primary server in the form of a special Puppet code file called a manifest. This is the information the primary server uses to compile a catalog — a JSON document describing the desired state of a specific agent node. Each agent requests and receives its own individual catalog and then enforces that desired state on the node it’s running on. In this way, Puppet applies changes all across your infrastructure, ensuring that each node matches the state you defined with your Puppet code. The agent sends a report back to the primary server.
You keep nearly all of your Puppet code, such as manifests, in modules. Each module manages a specific task in your infrastructure, such as installing and configuring a piece of software. Modules contain both code and data. The data is what allows you to customize your configuration. Using a tool called Hiera, you can separate the data from the code and place it in a centralized location. This allows you to specify guardrails and define known parameters and variations, so that your code is fully testable and you can validate all the edge cases of your parameters. If you have just joined an existing team that uses Puppet, take a look at how they organize their Hiera data.
All of the data generated by Puppet (for example facts, catalogs, reports) is stored in the Puppet database (PuppetDB). Storing data in PuppetDB allows Puppet to work faster and provides an API for other applications to access Puppet’s collected data. Once PuppetDB is full of your data, it becomes a great tool for infrastructure discovery, compliance reporting, vulnerability assessment, and more. You perform all of these tasks with PuppetDB queries.
Open source Puppet vs Puppet Enterprise (PE)
Puppet Enterprise (PE) is the commercial version of Puppet and is built on top of the open-source Puppet platform. Both products allow you to manage the configuration of thousands of nodes. Open source Puppet does this with desired state management. PE provides an imperative, as well as declarative, approach to infrastructure automation.
If you have a complex or large infrastructure that is used and managed by multiple teams, PE is a more suitable option, as it provides a graphical user interface, point-and-click code deployment strategies, continuous testing and integration, and the ability to predict the impact of code changes before deployment.
Puppet Repo Add:
wget https://apt.puppet.com/puppet7-release-focal.deb
sudo dpkg -i puppet7-release-focal.debPuppet Server Installation:
sudo yum install puppetserver
or
sudo apt-get install puppetserverStart the Puppet Server service:
sudo systemctl start puppetserver
or
sudo service puppetserver startPuppet Agent Installation on the servers which need to be managed:
Use the link to add repository: https://puppet.com/docs/puppet/5.5/puppet_platform.html
Yum – sudo yum install puppet-agent
Apt – sudo apt-get install puppet-agent